As organizations adopt data science and machine learning at scale, maintaining data model integrity becomes essential for trustworthy and accurate AI systems. This blog explores how data science foundations, data lakes, and data warehouses support reliable analytics, and how machine learning models depend on high quality, consistent data. It further examines the role of cryptography in protecting data integrity, confidentiality, and authenticity across the AI lifecycle. By combining real world use cases with emerging technologies such as privacy preserving machine learning, blockchain, and quantum cryptography, the article outlines a practical approach to building secure, governed, and resilient AI systems.
Understanding the Basics: Data Science, Data Lake, and Data Warehouse
In today's world, data is the driving force behind many business decisions and strategies. Data science, data lake, data warehouse, machine learning, data model integrity, and cryptography all play a crucial role in managing and protecting this valuable asset while ensuring ethical AI practices and model governance. Ensuring data model integrity is of utmost importance as it guarantees the accuracy, consistency, and reliability of the data. In this article, we will explore the basics of data science, data lake, and data warehouse, delve deeper into machine learning and its connection to data model integrity, understand the intersection of cryptography and data model integrity, and examine practical applications of cryptography in ensuring data model integrity. By the end, you will have a comprehensive understanding of how these concepts work together to safeguard the integrity of data.
What is Data Science?
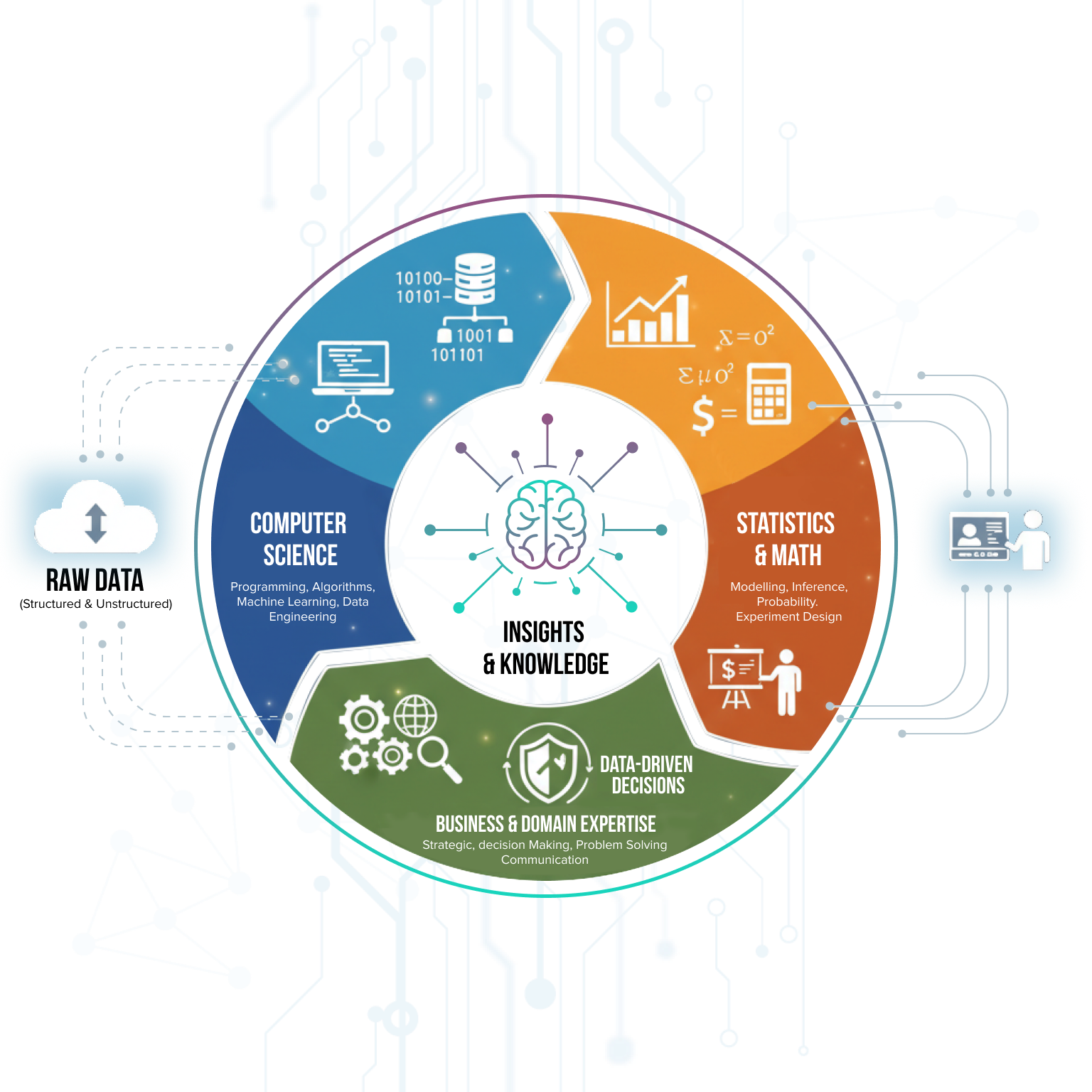
Data science is an interdisciplinary field that combines various techniques and processes to extract insights and knowledge from structured and unstructured data. It involves the application of statistical analysis, data visualization, and machine learning algorithms to uncover valuable patterns and trends hidden within the data. Data scientists play a critical role in transforming raw data into actionable information that can drive business decisions and innovation.
Data science is a rapidly growing field that has gained significant attention in recent years. With the exponential increase in data generation, organizations across industries are recognizing the importance of leveraging data to gain a competitive advantage. Data scientists use their expertise in programming languages like Python and R, along with their knowledge of statistical modeling techniques, to analyze large datasets and derive meaningful insights. They are skilled in identifying trends, patterns, and correlations in data, which can help businesses make informed decisions and optimize their operations. They also leverage generative AI tools for code generation, automated report creation, and enhanced data exploration, while implementing MLOps practices to ensure model reproducibility and governance.
In addition to their technical skills, data scientists also possess strong problem-solving and communication abilities. They are adept at formulating research questions, designing experiments, and interpreting the results in a way that is understandable to both technical and non-technical stakeholders. By effectively communicating their findings, data scientists enable organizations to make data-driven decisions and drive innovation.
The Role of Data Lake in Data Science
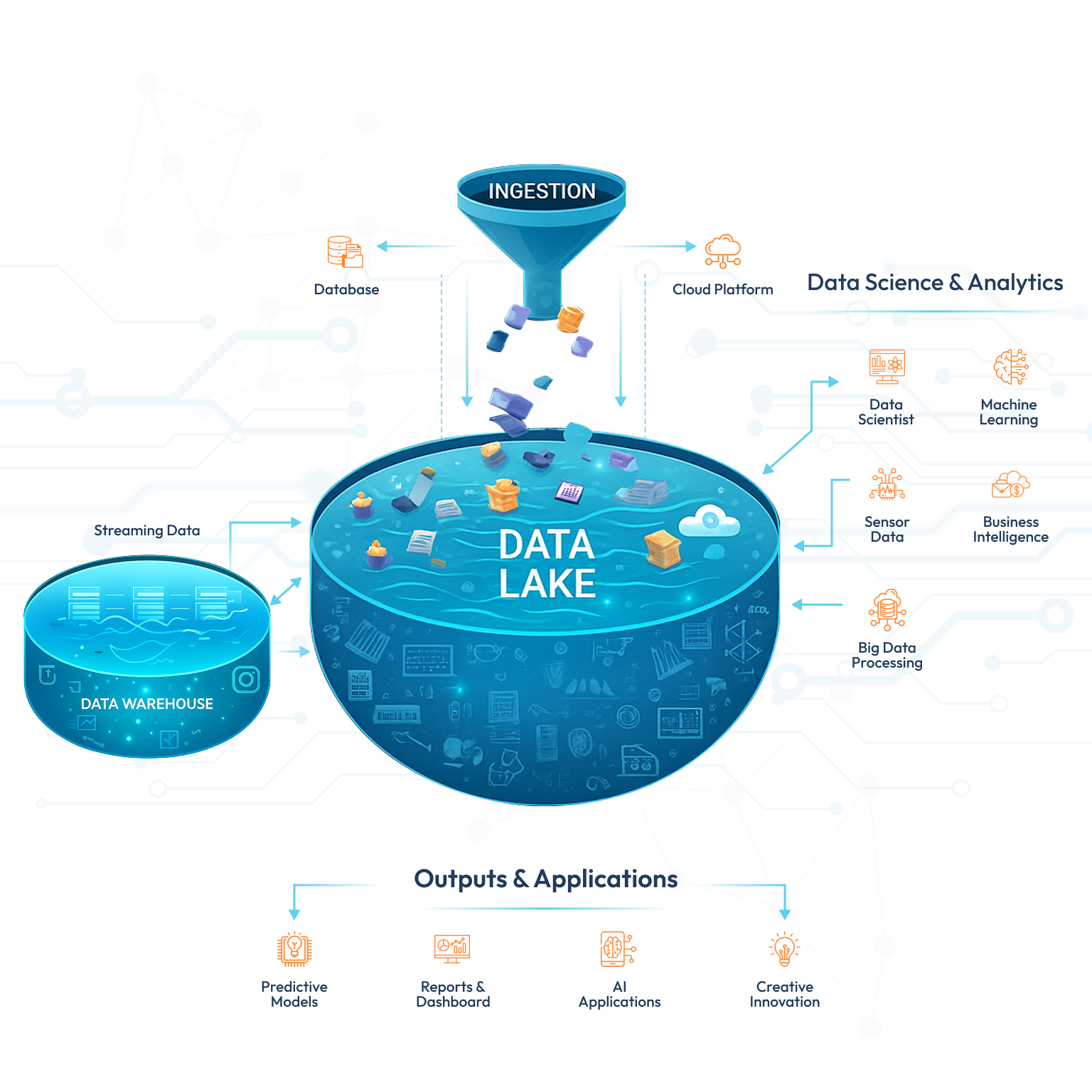
A data lake is a central repository that stores large amounts of raw and unprocessed data from various sources. It enables data scientists to access and analyze diverse datasets without the need for extensive data preparation. Unlike a traditional data warehouse, which relies on a predefined schema, a data lake allows for flexible data exploration and experimentation. This flexibility is essential in data science as it empowers data scientists to explore and discover new insights that may not have been initially considered.
Data lakes are designed to accommodate structured, semi-structured, and unstructured data, making them ideal for storing a wide variety of data types. They provide a scalable and cost-effective solution for storing and processing big data. With the ability to store data in its raw form, data lakes offer a high degree of flexibility and agility, allowing data scientists to quickly access and analyze data without the need for extensive data transformation.
One of the key advantages of data lakes is their ability to capture and store data from multiple sources in its original format. Contemporary Data Lakes also support real-time streaming data ingestion, automated data cataloging, and integrated ML model training capabilities, enabling end-to-end machine learning pipelines.This means that data scientists can work with data from various systems, such as customer relationship management (CRM) systems, transactional databases, social media platforms, and IoT devices, without the need for complex data integration processes. By eliminating the need for data transformation upfront, data lakes streamline the data analysis process and enable data scientists to focus on extracting insights and value from the data.
The Importance of Data Warehouse in Data Management
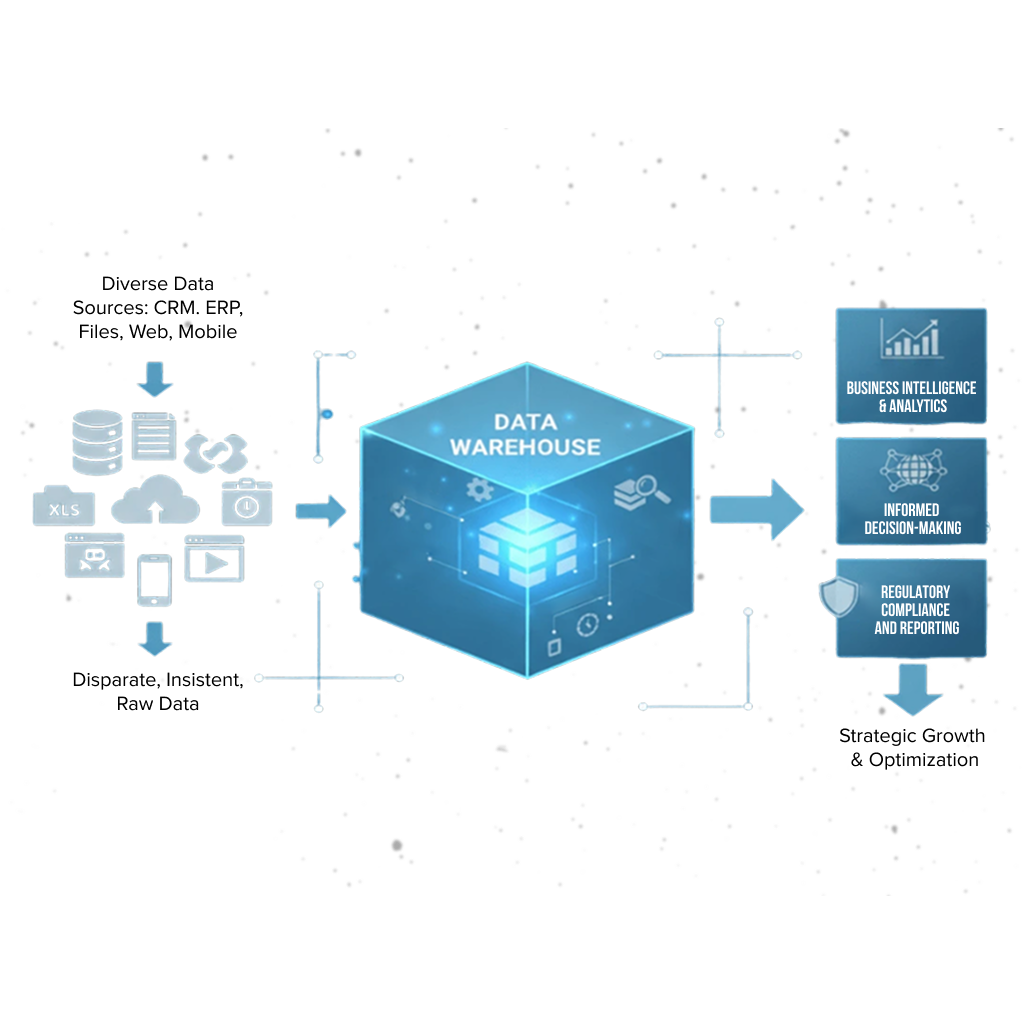
A data warehouse, on the other hand, is a structured and organized database that serves as a consolidated repository for business-related data. It is designed to support reporting, analytics, and decision-making processes. Data warehouses provide a consistent and reliable view of the data by integrating data from various sources, transforming it into a standardized format, and loading it into a dimensional model. This structured approach ensures data consistency and makes it easier to query and analyze the data for business intelligence purposes.
Data warehouses play a crucial role in data management by providing a single source of truth for the organization. They enable businesses to consolidate data from disparate sources and create a unified view of their operations. By integrating data from different systems, such as sales, marketing, finance, and supply chain, data warehouses provide a comprehensive and holistic view of the organization's performance.
Data warehouses play a crucial role in data management by providing a single source of truth for the organization. They enable businesses to consolidate data from disparate sources and create a unified view of their operations. By integrating data from different systems, such as sales, marketing, finance, and supply chain, data warehouses provide a comprehensive and holistic view of the organization's performance.
Data warehouses are optimized for query performance, allowing users to retrieve and analyze large volumes of data quickly. They employ various optimization techniques, such as indexing, partitioning, and materialized views, to enhance query performance and reduce response times.This enables business users to run complex analytical queries and generate reports in real-time, supporting data-driven decision-making processes.
Furthermore, data warehouses support data governance and data quality initiatives. They enforce data standards and ensure data consistency by applying data cleansing and data validation rules. This helps organizations maintain high-quality data and ensures that the data used for reporting and analysis is accurate and reliable.
Diving Deeper into Machine Learning and Data Model Integrity
Deep Dive into Analysis Techniques
Machine learning is a subset of artificial intelligence that focuses on developing algorithms to enable computers to learn and make predictions or decisions without explicit programming. This includes traditional ML, deep learning with neural networks, and modern generative AI systems that can create text, images, and code.
It involves the use of statistical techniques and mathematical models to train machines on large datasets and generate insights or predictions. Machine learning algorithms can identify patterns and correlations in data, allowing businesses to make data-driven decisions and automate processes.
Machine learning has become increasingly popular in various industries due to its ability to analyze vast amounts of data quickly and efficiently. It has revolutionized fields such as finance, healthcare, marketing, and transportation, among others. By leveraging machine learning algorithms, businesses can gain valuable insights that can drive innovation, improve customer experiences, and optimize operations.
One of the key advantages of machine learning is its ability to adapt and improve over time. As the machine is exposed to more data, it can learn from its experiences and refine its predictions or decisions. This iterative learning process allows the machine to continuously improve its performance, making it a powerful tool for solving complex problems and making accurate predictions.
Machine learning algorithms can be broadly categorized into several types: supervised learning, unsupervised learning, reinforcement learning, self-supervised learning, and transfer learning. Modern approaches also include few-shot learning, zero-shot learning, and multi-modal learning that can process different data types simultaneously.
- Supervised learning involves training the machine using labeled data, where the desired output is known.
The Connection between Machine Learning and Data Model Integrity
Machine learning algorithms heavily rely on high-quality and accurate data to produce reliable results. Therefore, maintaining data model integrity is crucial in ensuring the effectiveness of machine learning models. Data inconsistencies, errors, or biases can significantly impact the performance and reliability of machine learning algorithms. Data scientists must ensure data quality by implementing data cleaning techniques, handling missing values, and validating the integrity of the data used for training and testing the models.
Data cleaning is an essential step in the machine learning process. It involves identifying and correcting errors or inconsistencies in the data through both manual techniques and automated data quality monitoring systems. Modern approaches include AI-powered anomaly detection for data quality issues and automated bias detection in training datasets. This can include removing duplicate records, handling missing values, and addressing outliers. Data cleaning ensures that the machine learning model is trained on accurate and reliable data, which improves the accuracy and performance of the model.
In addition to data cleaning, data scientists also need to handle missing values appropriately. Missing values can occur due to various reasons, such as data collection errors or incomplete records. There are several techniques for handling missing values, including imputation, where missing values are replaced with estimated values based on the available data. Imputation methods can be simple, such as replacing missing values with the mean or median, or more complex, such as using regression models to predict missing values based on other variables. Advanced imputation techniques now include deep learning-based methods, such as autoencoders and generative models, which can learn complex patterns to predict missing values more accurately than traditional statistical methods.
Another important aspect of maintaining data model integrity is validating the integrity of the data used for training and testing the machine learning models. This involves checking for data biases, inconsistencies, or errors that may affect the performance of the model. Data scientists need to carefully analyze the data and ensure that it represents the real-world scenario accurately. They may need to perform data audits, conduct exploratory data analysis, and validate the data against external sources to ensure its integrity.
The Intersection of Cryptography and Data Model Integrity
Understanding Cryptography in Data Protection
Cryptography is the practice of securing communication and data from unauthorized access or modification. It involves using mathematical algorithms and protocols to encrypt sensitive information, making it indecipherable to anyone without the proper decryption keys. Cryptography plays a crucial role in data protection by ensuring the confidentiality, integrity, and authenticity of the data. It provides a robust defense against unauthorized access, data breaches, and tampering.
When it comes to data protection, cryptography acts as a shield, safeguarding sensitive information from prying eyes. By encrypting data, it becomes virtually impossible for unauthorized individuals to understand or make sense of the information. This is especially important in today's digital age, where data is constantly being transmitted and stored. One of the key aspects of cryptography is its ability to ensure confidentiality. By encrypting data, it becomes scrambled and unreadable to anyone without the proper decryption key. This means that even if an attacker gains access to the encrypted data, they will not be able to understand its contents without the key. This provides a strong layer of protection, especially when dealing with sensitive information such as personal identification numbers or financial Data.
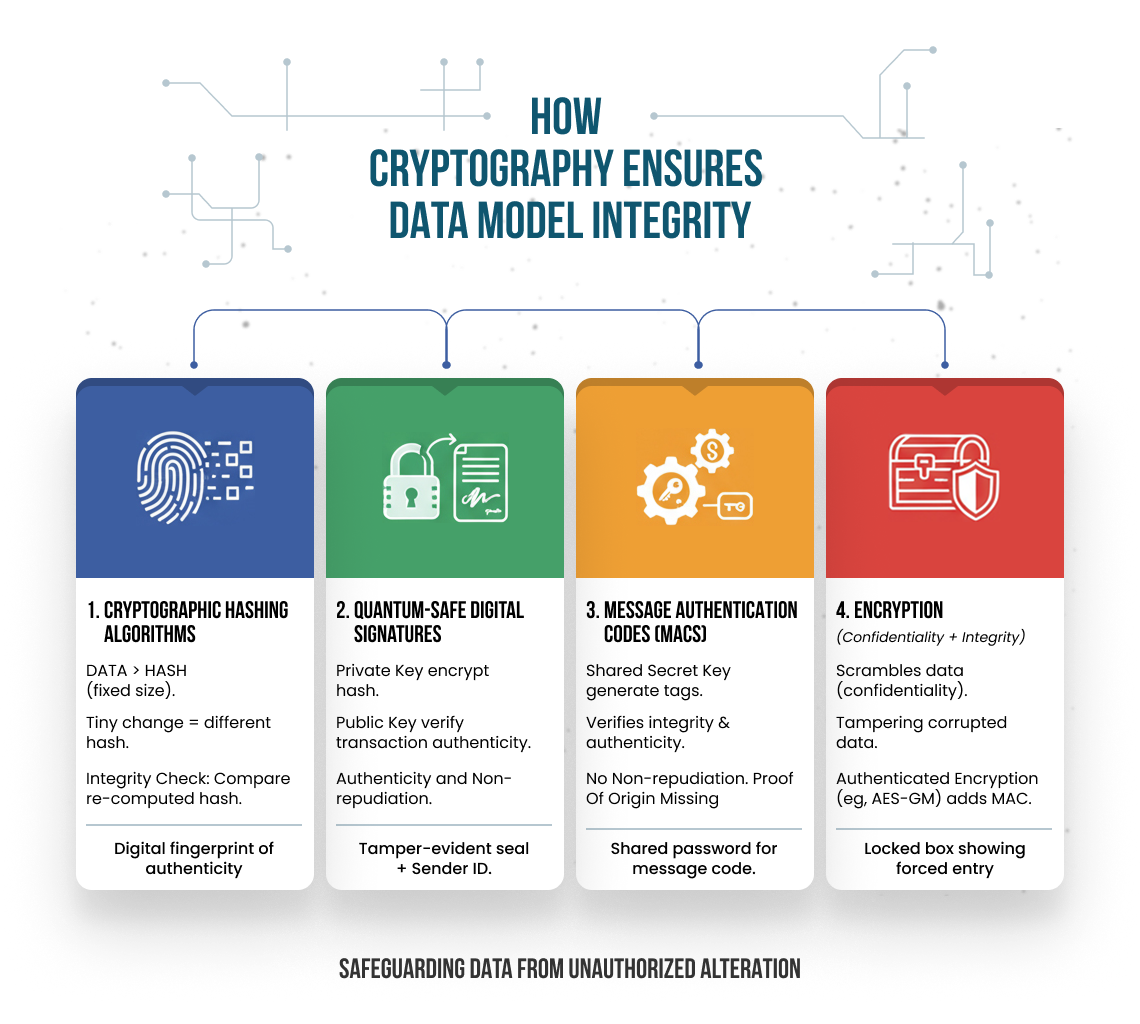
How Cryptography Ensures Data Model Integrity

Cryptographic techniques, such as digital signatures and hash functions, can be used to ensure the integrity of data models. Modern applications include homomorphic encryption for privacy-preserving machine learning, differential privacy for protecting individual data points in training sets, and secure multi-party computation for collaborative ML without sharing raw data.
Digital signatures provide a way to verify the authenticity and integrity of data by attaching a unique cryptographic signature to it. This signature can be verified using a corresponding public key, ensuring that the data has not been tampered with or modified.
Practical Applications: Ensuring Data Model Integrity with Cryptography
Cryptography plays a crucial role in ensuring data model integrity across various industries and organizations. By implementing cryptographic techniques, sensitive data can be protected and its integrity maintained throughout the entire data lifecycle.
Case Studies of Cryptography in Data Model Integrity
In the healthcare sector, cryptographic techniques are extensively used to safeguard patient data. Modern applications include AI-powered medical imaging analysis with privacy-preserving techniques, federated learning for drug discovery across institutions, and differential privacy in electronic health records analysis. This ensures that patient information remains confidential and cannot be accessed or tampered with by unauthorized individuals. By employing encryption algorithms, healthcare organizations can securely store and transmit sensitive patient data, maintaining the privacy and integrity of the data model.
Financial institutions also heavily rely on cryptography to ensure the integrity of their data models. Modern fintech applications leverage machine learning for algorithmic trading, fraud detection using deep learning models, robo-advisors powered by reinforcement learning, and real-time risk assessment using ensemble methods and neural networks.
By encrypting financial transactions, organizations can prevent unauthorized access and fraud. Cryptographic protocols are employed to secure online banking, credit card transactions, and other financial activities, providing a robust defense against potential threats.
Another industry that benefits from the use of cryptography is the supply chain sector. In this industry, ensuring the authenticity and integrity of product information is of utmost importance.
Cryptographic techniques are employed to verify the origin and integrity of product data, making it possible to trace the entire supply chain and detect any potential tampering or counterfeit products. This not only ensures the safety of consumers but also builds trust and confidence in the supply chain process.
Future Trends in Cryptography and Data Model Integrity
The field of cryptography is continuously evolving to keep up with advancements in technology. Simultaneously, AI and machine learning are advancing rapidly with developments in foundation models, multimodal AI, edge computing, and quantum machine learning.

Partner with Datopic to Unlock Edge Excellence
At Datopic Technologies,we ensure data-driven innovation remains secure and ethical - combining machine learning, data model integrity, and cryptography to power reliable, governed, and resilient AI systems.
👉 Explore Services
👉 Request a Consultation
Let Datopic help you build the edge-first architecture your users deserve.